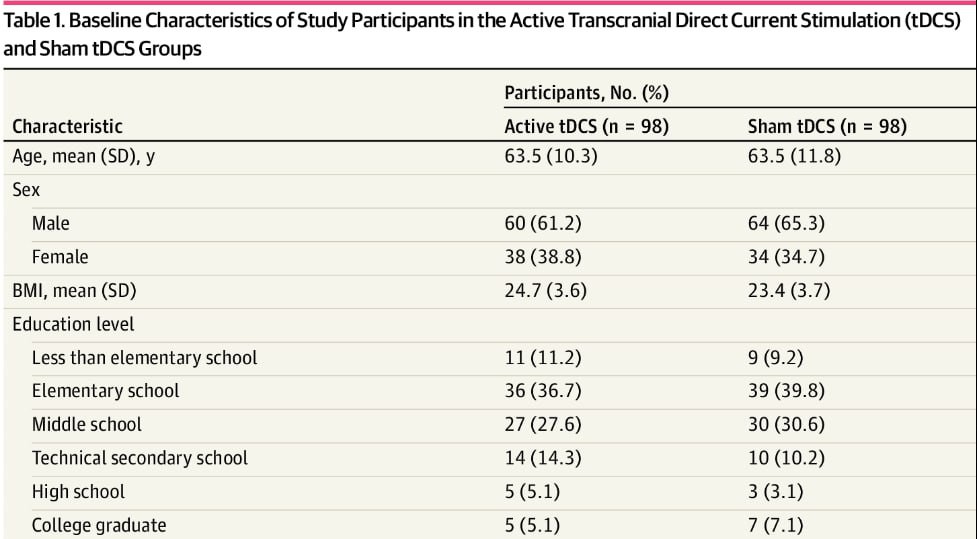
Перед нами — вырезка из таблицы №1 из статьи, описывающей результаты сравнительного исследования, с исходными клинико-статистическими характеристиками пациентов. Ссылка на статью
Представлена описательная статистика для количественных переменных «Возраст» (Age) и «ИМТ» (BMI), для категориальных переменных «Пол» (Sex) и «Уровень образования» (Education level).
Категориальные данные описаны с помощью абсолютного числа исследуемых, относящихся к каждой категории (например, мужчин и женщин), в скобках — процентная доля данной категории в структуре группы. Можно было бы отметить способ представления данных через запятую рядом с названием показателя, например, Sex, abs. (%), или в комментариях к таблице, однако это рутинное описание, и такое уточнение, вероятно, посчитали избыточным.
Обратим внимание на количественные показатели. Они представлены средними значениями (mean) и стандартными отклонениями (SD). Размещение SD в скобках после среднего значения соответствует современным требованиям, в частности, указанным в правилах SAMPL:
Summarize data that are approximately normally distributed with means and standard deviations (SD). Use the form: mean (SD), not mean ± SD.
Несмотря на эти рекомендации, ± между средним значением и SD до сих пор широко распространено, в том числе в таких авторитетных журналах, как New England Journal of Medicine. Как писать — остается на усмотрение авторов статьи и редакции конкретного журнала.
P.S. Внимательные читатели могут отметить еще один нюанс — отсутствие единиц измерения для ИМТ, однако они указаны в комментариях к таблице: BMI calculated as weight in kilograms divided by height in meters squared.
Добавить комментарий