Не раз уже мы обсуждали, как важно правильное понимание статистических терминов. И уже разбирали некоторые из них: p-значение, доверительный интервал, доли и частоты и другие.
А сегодня мы попробуем простыми словами интерпретировать главную часть вывода — о наличии различий. Казалось бы, что здесь сложного? Ну, написано: «группы статистически значимо различались по уровню гемоглобина». Значит, в одной группе показатель больше, в другой меньше. Но потом мы видим, что медианы показателя в обеих группах одинаковы! И тогда возникает вопрос: откуда же взялись различия?
А если точнее сформулировать этот вопрос: о различиях ЧЕГО мы делаем вывод, применяя разные статистические методы?
1️⃣ Различия, установленные параметрическими методами
Начнём с различий сравниваемых групп по количественному признаку, установленных с помощью параметрических методов: t-критерия Стьюдента, дисперсионного анализа.
Их неспроста называют методами сравнения средних. Если различия выявлены, то можно сделать вывод, что СРЕДНЕЕ значение показателя в одной группе выше, чем в другой. Если средние значения — одинаковые, то различий не будет.
От величины разницы между средними будет напрямую зависеть выраженность различий между группами. Поэтому разность средних (mean difference или difference in mean, MD) с 95% доверительным интервалом (ДИ, CI) является важным элементом вывода. ДИ, как и p-value, позволяет судить о значимости различий: если обе его границы либо выше, либо ниже 0 — различия статистически значимы. Если нижняя граница <0, а верхняя — >0, то различия статистически незначимы.
👉 Например:
MD 2.3 (95% CI: 1.5 to 3.1) — различия статистически значимы, p<0.05
MD 1.2 (95% CI: -0.5 to 2.9) — различия статистически незначимы, p>0.05
Попробуйте подставить правильные значения p-value на рисунке ниже:
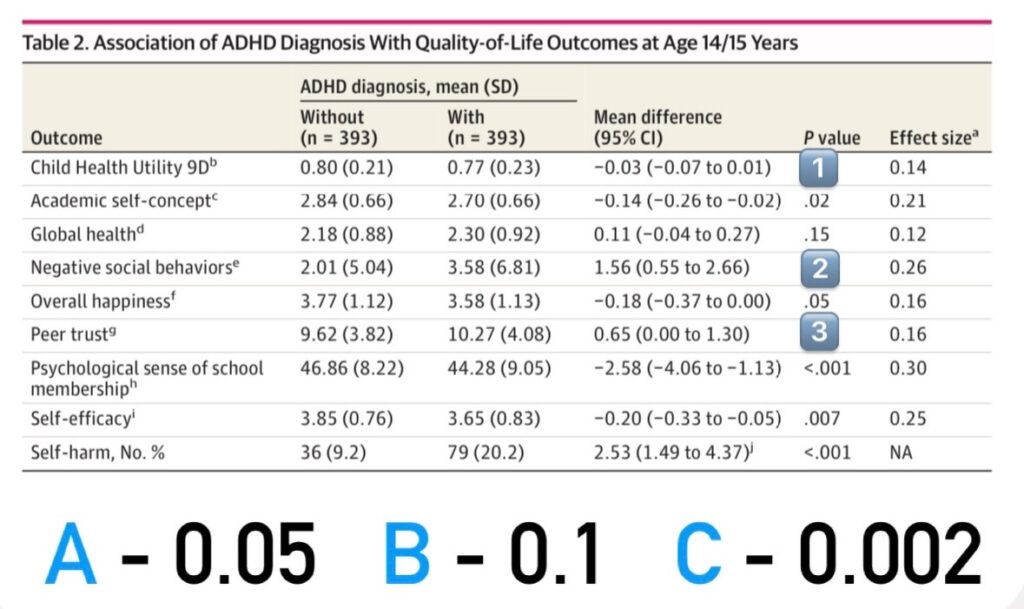
Расставьте правильные значения p вместо цифр, исходя из разности средних (правильный ответ в конце поста)
2️⃣ Различия, установленные ранговыми методами
Если различия количественного показателя установлены с помощью непараметрического рангового критерия, например, Манна-Уитни, то здесь различия средних уже не так важны. Дело в том, что этот критерий предполагает замену истинных значений показателя на ранги — порядковый номер в ряду из всех значений.
👉 Например, вместо двух групп:
1, 5, 9, 100 и 4, 7, 8, 10
будут сравниваться ранги этих значений:
1, 3, 6, 8 и 2, 4, 5, 7.
Как мы видим, огромное значение «100» имеет ранг «8» — это восьмое по счёту число из всех чисел обоих групп. И этот ранг всего лишь на 1 больше ранга «7» у числа «10», которое будет седьмым по счёту.
Поэтому непараметрические критерии обладают таким свойством, как робастность — устойчивость к выбросам. Так как вместо истинных значений мы сравниваем ранги. Различия, установленные с помощью критерия Манна-Уитни, означают, что РАНГИ значений в одной группе выше рангов в другой группе.
👉 Сравним 2 ситуации:
🅰️ 1, 3, 5, 7 и 2, 6, 8, 9,
🅱️ 1, 3, 5, 7 и 2, 6, 100, 500.
В случае «В» значения показателя во второй группе, конечно, намного выше, чем в «А». Но с точки зрения критерия Манна-Уитни это две равнозначные ситуации. Ведь ранги будут одни и те же:
1, 3, 4, 6 и 2, 5, 7, 8.
Потому и p-value, при сравнении групп в обеих ситуациях будет одинаковым.
При оформлении вывода по результатам применения таких критериев, наверное, было бы хорошо дополнить его значениями средних рангов или разности рангов. Ведь именно они, а не медианы, показывают, в какой группе показатели выше, а в какой — ниже. Но такой практики пока не сложилось.
3️⃣ Различия, выявленные при сравнении зависимых (связанных) групп
О каких различиях мы говорим, выполняя сравнение зависимых групп — в анализе «До-После»?
В этом случае мы определяем, что ИЗМЕНЕНИЕ показателя в одном направлении (например, увеличение) происходит чаще и в большей степени, чем в противоположном направлении. В основе оценок — не средние значения или ранги в группах, а РАЗНОСТЬ показателей до и после.
👉 Например, после лечения анемии среди 100 пациентов были получены такие результаты:
▪️у 60 человек уровень гемоглобина увеличился, на 20 г/л,
▪️у 20 человек увеличился на 30 г/л,
▪️у 10 человек он остался таким же, каким был,
▪️у 10 человек снизился на 20 г/л.
Мы можем посчитать среднюю разность показателей, получим:
(60*20 + 20*30 + 10*0 — 10*20)/100= +16.
Получается, что в среднем уровень показателя увеличился на 16 г/л — это значение называется средней разностью (paired mean difference, mean in difference). Средняя разность — >0, значит увеличение было более выраженным, чем уменьшение.
Дополнительно определяются границы 95% ДИ для средней разности. Если обе границы либо выше 0, либо ниже 0 — изменения показателя статистически значимы. Если нижняя граница меньше 0, а верхняя — выше, то делаем вывод о незначимых изменениях.
Также можно отметить долю случаев увеличения и уменьшения: у 80 пациентов, или в 80% случаев, уровень гемоглобина увеличивался, в 10% случаев — снижался.
❗️Важно, что если показатель изменяется в одном направлении даже на очень малую величину, но у большинства пациентов, изменения могут быть статистически значимыми! В таких случаях средние значения, медианы в зависимых группах будут практически одинаковыми, а p<0.05.
👉 Например, из 100 пациентов у 90 уровень гемоглобина увеличился всего на 1 г/л. Клинически эти изменения ничтожны. А по результатам применения методов сравнения «до-после» — будут статистически значимыми.
Итак, при сравнении зависимых групп мы делаем вывод о наличии статистически значимых изменений. Дополняем вывод средней разностью показателей с 95% ДИ и (или) долей случаев снижения и увеличения показателя.
4️⃣ Различия, установленные при сравнении категориальных показателей
О чем говорят различия процентных долей, установленные с помощью критерия хи-квадрат Пирсона?
В этом случае мы сравниваем РАСПРЕДЕЛЕНИЯ исследуемых по категориям — фактическое распределение с теоретическим равномерным распределением.
👉 Например, сравниваем две группы пациентов по частоте анемии:
Группа А: 25%, или 20 человек из 80.
Группа Б: 43%, или 43 человека из 100.
Это фактическое распределение.
А равномерное распределение — такое, при котором частота анемии при тех же общих количествах пациентов была бы одинаковой в сравниваемых группах. Для его получения вначале определим общую частоту анемию среди всех пациентов:
(20+43)/(80+100) = 63/180 = 0.35 или 35%.
Теперь посчитаем, сколько должно было быть пациентов с анемией в каждой группе, чтобы их доля составляла 35%:
Группа А: 0.35*80 = 28 человека.
Группа Б: 0.35*100 = 35 человек.
Итак, критерий хи-квадрат Пирсона сравнивает распределение двух групп по 80 и 100 человек:
Неравномерное фактическое 20/80 (25%) и 43/100 (43%)
против
Равномерного теоретического 28/80 и 35/100 (по 35%).
В результате p-значение составляет 0.012, что позволяет сделать вывод о статистически значимых различиях. Распределение исходов между сравниваемыми группами отличается от равномерного, а значит является неравномерным: в одной группе исходы встречаются чаще, чем в другой.
Другой способ оценить различия процентных долей в двух группах — сопоставить их напрямую. При этом широко используется понятие «риск». По сути, риск — это та же частота исхода в группе. Но, называя частоту риском, мы как бы предполагаем, какие значения частоты ожидаются в будущем, при повторении эксперимента.
Здесь выделим 2 основных метода:
🔹Разность рисков (Risk difference, RD) — рассчитывается так:
Частота исходов в группе А — Частота исходов в группе В.
RD показывает, НА СКОЛЬКО частота (риск) исходов выше в одной группе, чем в другой.
👉 Для нашего примера:
RD = 25 — 43 = -18%
Вывод можно сформулировать так:
Риск анемии в группе А был ниже на 18%, чем в группе Б.
Как мы видим, RD измеряется в % и может быть как положительным (если частота исхода больше в группе А), так и отрицательным (если частота исхода больше в группе Б).
🔹Относительный риск (Relative risk, RR) — рассчитывается как отношение частоты исхода в группе А на частоту исхода в группе Б.
Показывает, ВО СКОЛЬКО раз частота (риск) исхода в одной группе выше, чем в другой.
Если значения RR больше 1, то вывод формируется очень просто. Например, если RR = 2, то риск исхода в группе А больше в 2 раза по сравнению с риском в группе Б.
Если значения RR меньше 1, то вывод делается о снижении риска в группе А по сравнению с группой Б в 1/RR раза. Например, RR = 0.25 означает, что риск исхода в группе А ниже риска в группе Б в 4 раза (т.к. 1/0.25 = 4).
👉 Для нашего примера:
RR = 25 / 43 = 0.58
Значит, можно сделать вывод о том, что риск анемии в группе А будет в 1.72 раза ниже, чем в группе Б (т.к. 1/0.58 = 1.72).
Для RD и RR обязательно рассчитываются границы 95% ДИ.
Если обе границы RD либо ниже, либо выше 0 — различия статистически значимы. Если нижняя граница <0, верхняя — >0, то различия статистически незначимы.
Если обе границы RR либо ниже, либо выше 1 — различия статистически значимы. Если нижняя граница <1, верхняя — >1, то различия статистически незначимы.
👉 Для нашего примера:
Границы 95% ДИ для RR: от 0.37 до 0.9, для RD: от -30.8 до 4.0%.
В обоих случаях границы ДИ свидетельствуют о статистической значимости различий: у RR не пересекают 1, у RD не пересекают 0.
Итак, мы разобрали основные случаи сравнения показателей между 2 группами. Понимая, что на самом деле сравнивается и о чем говорят выявленные различия, мы сможем более качественно сформулировать вывод, дополнив p-значение альтернативными оценками.
(Правильный ответ на задание: 1 — В, 2 — С, 3 — А)
Добавить комментарий