К сожалению, в природе существует такое явление, как «Корявая База Данных». Приведение её в порядок способно значительно удлинить и усложнить путь исследователя к заветной статье или диссертации. А статистик-профессионал, получив такую базу для работы, обливается горючими слезами, понимая, что впереди его ждёт много потерянного времени.
Причины возникновения КБД могут быть разными:
- незнание принципов формирования хорошей базы,
- небрежность исследователя («и так сойдет!» или «пока так запишу, а потом исправлю»),
- выгрузка базы из информационной системы, куда пользователи вносили данные, не заморачиваясь.
Иногда на доработку корявой базы до приемлемого качества могут уходить дни и даже недели!
А сможет ли искусственный интеллект (ИИ) превратить корявую базу данных в хорошую, сэкономив время и нервы (а иногда и деньги) исследователям?
Мы решили проверить это.
Входные условия:
ИИ — DeepSeek, бесплатный аккаунт.
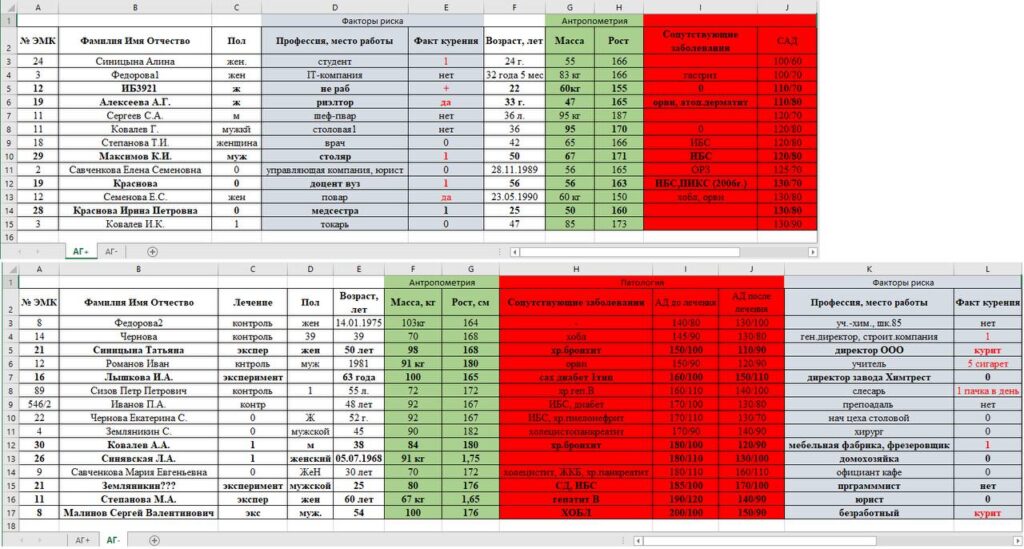
- Корявая база — специально подготовленная таблица в .xlsx, где мы постарались создать все возможные проблемы:
- Разместили данные двух групп на разных листах.
- Расположили колонки на каждом листе в своём порядке, причем часть показателей создали только для одной группы, а для другой — нет.
- Пропустили некоторые значения, которые можно определить из других значений. Например, пол пациентов в некоторых случаях можно определить из ФИО.
- Закодировали значения одного и того же показателя максимально по-разному: текстом, буквами, цифрами, датами, с единицами измерения, без них и т.д.
- В текстовых значениях сделали ошибки, опечатки («мужкй», «кнтроль»)
- Сделали многоэтажные заголовки у колонок (например, сверху — Антропометрия, ниже — Масса, Рост).
Промпт придумали простенький:
Проанализируй набор данных, исправь в нем ошибки и подготовь базу данных для анализа в статистической программе. Выведи результат в табличной форме.
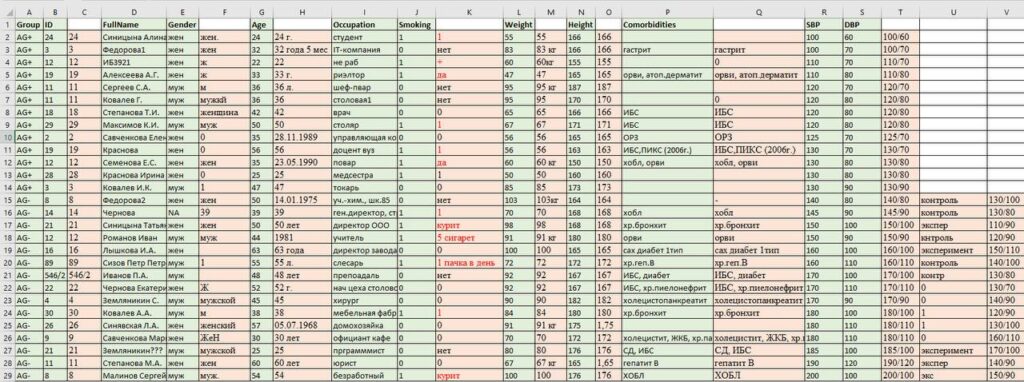
ИИ работал на протяжении нескольких минут (я успел неспеша выпить чашку чая) и выдал результат, который представлен на картинке к этому посту. Сразу отмечу, что формат был, как и заказано, табличный, поэтому новые данные без проблем скопипастились в новую базу.
Для удобства мы перенесли в новую базу и исходные данные (красные), которые сопоставили с обработанными ИИ (зеленые).
Что получилось?
- Данные объединены на одном листе.
- Названия колонок размещены в одной верхней строке.
- ИИ разобрался, какие колонки соответствуют одному и тому же показателю, даже если их названия были разными и сокращенными (например, «САД» и «АД до лечения»), и правильно их объединил.
- Все колонки переназваны по-английски, попутно исправлены некоторые ошибки. Например, в колонке САД было указано как САД, так и ДАД, через косую черту. В итоге сформированы 2 столбика: SBP и DBP с корректным переносом значений.
- Правильно закодированы значения категориальных данных — единообразно, с сохранением смысла. Текстовые значения и символы в переменной «Факт курения» заменены числами 0 и 1. Переменная «Пол» закодирована значениями «муж» и «жен».
- Значения количественных переменных приведены к одной шкале измерения (Рост 1,75 превратился в 175), убраны единицы измерения.
- Пропущенные значения переменной «Пол» были восстановлены по ФИО.
- Даты в переменной «Возраст» переведены в значения возраста на сегодняшний день.
- ИИ создал новую переменную «Group», где разделил пациентов на гипертоников (AG+) и нормотоников (AG-) по исходному САД.
Что НЕ получилось?
- Категориальная мультиномиальная переменная с текстовыми значениями «Профессия, место работы» осталась без изменений. ИИ не стал перекодировать текст в числа или собирать отдельные профессии в группы.
- У одной пациентки в колонке «Пол» мы продублировали её возраст. В итоге ИИ значение «39» убрал, но пол почему-то по фамилии определять не захотел (хотя это было возможно) и написал просто «N/A».
- В сложной переменной «Сопутствующие заболевания» с сочетаниями категорий, которые хорошо было бы разбинарить по разным столбикам, ИИ только заменил 0 на пустые ячейки, что само по себе может быть неверным действием (0 и пустота могли означать разные признаки, например, 0 — отсутствие в анамнезе сопутствующих заболеваний, пустота — отсутствие информации о сопутствующих заболеваний).
- Колонки «АД после лечения» и «Лечение», определенные только в одной группе, вообще не были добавлены в новую базу. Несмотря не небольшие недоделки, работой ИИ я остался доволен! За короткое время, бесплатно и без моего непосредственного участия были решены важные и сложные задачи:
- объединены и переназваны данные,
- перекодированы значения,
- восстановлены пропущенные данные.
- Разбинаривание и кодировку мультиномиальных переменных с текстовыми значениями придётся делать самому. Либо нужно доработать промпт, чтобы ИИ понял, как решать и эти проблемы.
- И будьте внимательны с теми показателями, которые есть только в одной группе. ИИ может не переносить их в общую базу.
Ну а лучше всего — сразу оформлять свою базу с соблюдением всех правил
Добавить комментарий